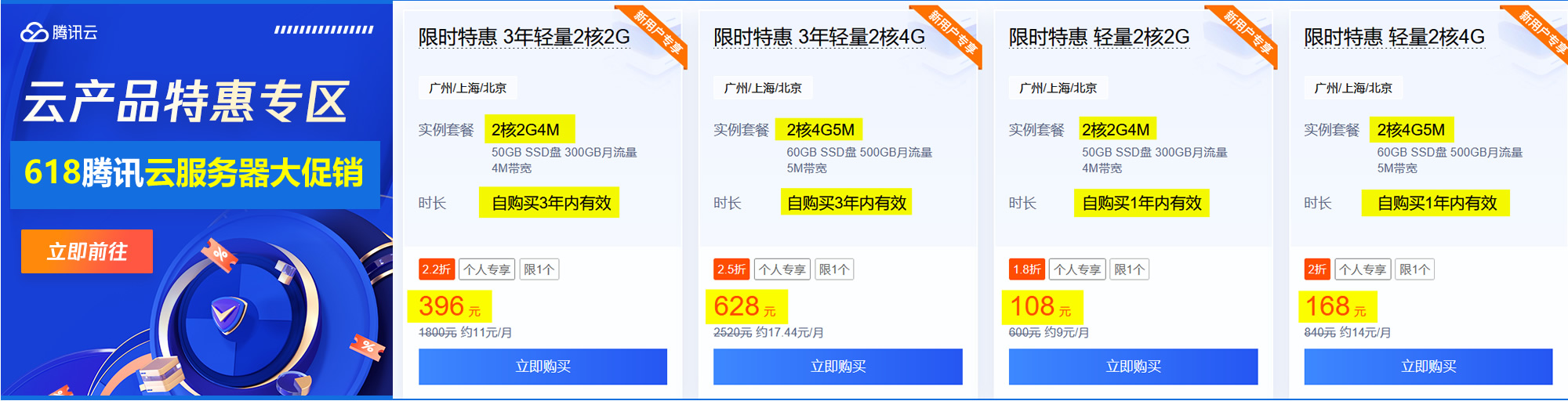


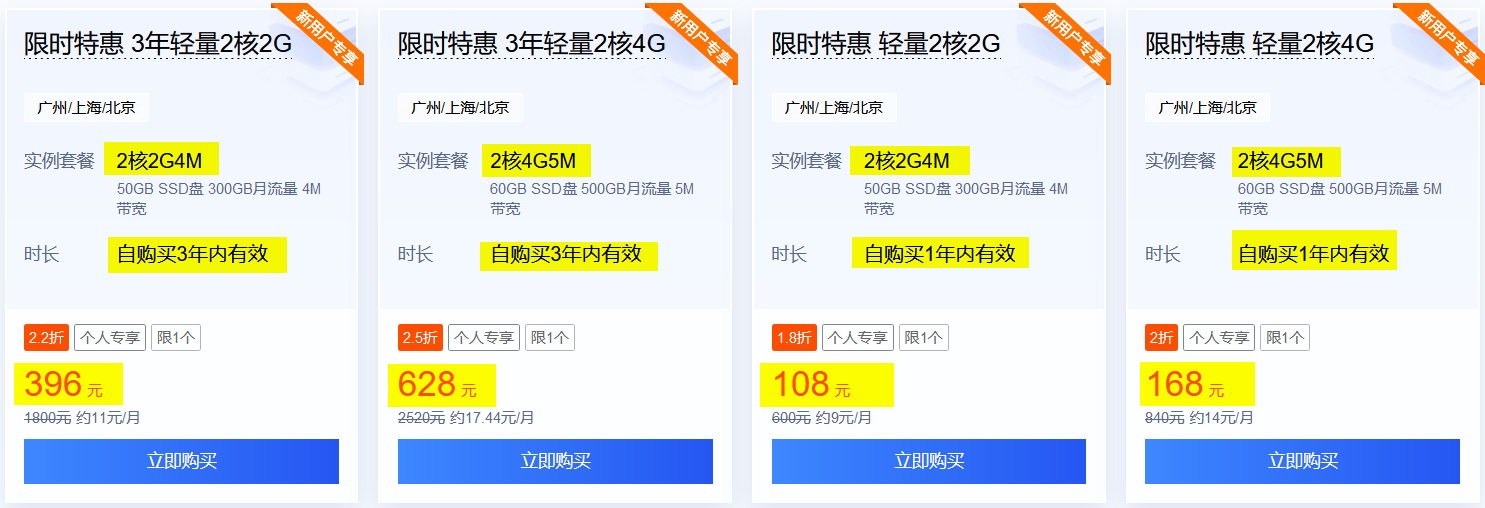

看淘宝搜索技术博客上的一篇文章《定向抓取漫谈》,对通用爬虫进行了简单的定义,如下:
抓取策略:那些网页是我们需要去下载的,那些是无需下载的,那些网页是我们优先下载的,定义清楚之后,能节省很多无谓的爬取。
更新策略:监控列表页来发现新的页面;定期check 页面是否过期等等。
抽取策略:我们应该如何的从网页中抽取我们想要的内容,不仅仅包含最终的目标内容,还有下一步要抓取的url。
抓取频率:我们需要合理的去下载一个网站,却又不失效率。
让我对“如何和爬虫对话 ”这个课题有了一些思考,下面归纳的主要用于迎合上面提到的爬虫“抓取策略”。
1、通过 robots.txt 和爬虫对话:搜索引擎发现一个新站,原则上第一个访问的就是 robots.txt 文件,可以通过 allow/disallow 语法告诉搜索引擎那些文件目录可以被抓取和不可以被抓取。
关于 robots.txt 的详细介绍:about /robots.txt
另外需要注意的是:allow/disallow 语法的顺序是有区别的
2、通过 meta tag 和爬虫对话:比如有的时候我们希望网站列表页不被搜索引擎收录但是又希望搜索引擎抓取,那么可以通过 <meta name=”robots” content=”noindex,follow”> 告诉爬虫,其他常见的还有 noarchive,nosnippet,noodp 等。
关于 meta tag 的更多介绍:Metadata Elements
3、通过 rel=“nofollow” 和爬虫对话:关于 rel=”nofollow” 最近国平写了一篇文章《如何用好 nofollow》很值得一读,相信读完之后你会有很大的启发。
4、通过 rel=“canonical” 和爬虫对话:关于 rel=”canonical” 谷歌网站站长工具帮助有很详细的介绍:深入了解 rel=”canonical”
5、通过网站地图和爬虫对话:比较常见的是 xml 格式 sitemap 和 html 格式 sitemap,xml 格式 sitemap 可以分割处理或者压缩压缩,另外,sitemap 的地址可以写入到 robots.txt 文件。
6、通过网站管理员工具和搜索引擎对话:我们接触最多的就是谷歌网站管理员工具,可以设定 googlebot 抓取的频率,屏蔽不想被抓取的链接,控制 sitelinks 等,另外,Bing 和 Yahoo 也都有管理员工具,百度有一个百度站长平台,内测一年多了仍旧在内测,没有邀请码无法注册。
另外,这里面还衍生出一个概念,就是我一直比较重视的网站收录比,所谓网站收录比=网站在搜索引擎的收录数/网站真实数据量,网站收录比越高,说明搜索引擎对网站的抓取越顺利。
暂时就想到这些,目的在于尝试性的探讨如何更有效的提高网站在搜索引擎的收录量。
权当抛砖引玉,欢迎各位补充!
备注:
网络爬虫(web crawler)又称为网络蜘蛛(web spider)是一段计算机程序,它从互联网上按照一定的逻辑和算法抓取和下载互联网的网页,是搜索引擎的一个重要组成部分。
作者:Bruce
文章来源:http://www.wuzhisong.com/blog/62

文章评论 本文章有个评论