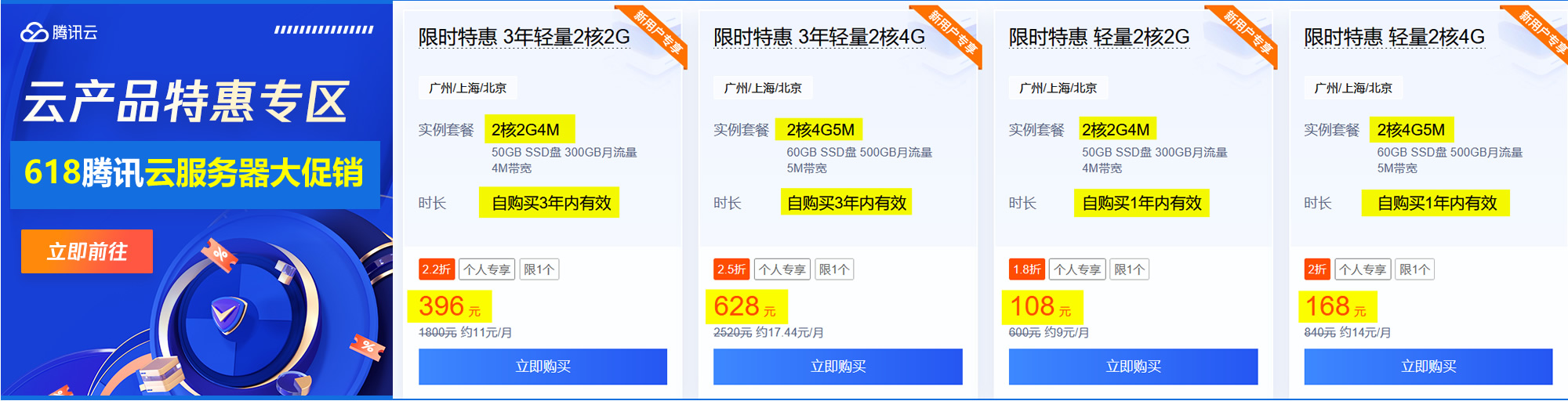


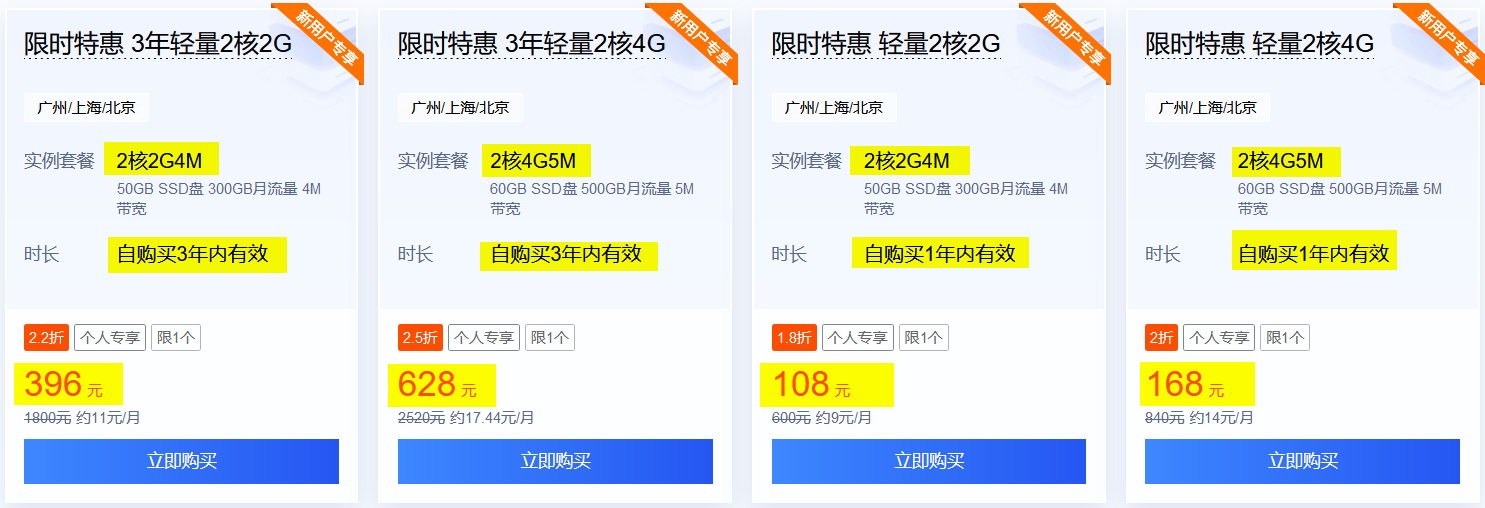

SEOer们要想更好的理解SEO,做好SEO的工作,学习和理解搜索引擎的基本架构和原理,是非常有必要的,下面我来讲一下搜索引擎的一些组成部分。通用的搜索引擎,一般包含了以下一些功能模块:
1,蜘蛛,即Spider,类似浏览器的程序,专门用来下载web页面
2,爬虫,即Crawler,用来自动跟踪所有页面中的链接
3,索引,即Indexer,专门用来分析蜘蛛和爬虫下载下来的web页面
4,数据库,存储下载的页面信息和处理过的页面信息
5,结果引擎,从数据库中抽取出搜索结果
6,Web服务器,用来处理用户的搜索交互请求的web服务器
不同的搜索引擎实现,某些地方可能有一定的差别,比如,蜘蛛+爬出+索引的组合功能就是通过一个单一的程序来实现的,它一边下载页面,一边分析出结果,并利用已有的链接来发现新的资源。当然,这些功能都是所有搜索引擎所固有的,所体现的SEO原则都是类似的。
下面对搜索引擎的功能模块进行分别阐述。
蜘蛛。这个功能模块专门用来下载页面,类似浏览器的功能。它们之间的区别在于,浏览器展现给用户的是各种形式的信息,包括文本的信息,图像的信息,视频的信息,等等;而对于蜘蛛来说,并没有一些可视化的组件,而是直接跟基本的html源代码打交道。大家可能都知道,一个标准的web浏览器都是带有html源文件查看的功能的。
爬虫。该功能模块专门用户发现每个页面中的所有链接。它的任务是,通过评估找到的链接,或者已定义的地址,来决定蜘蛛去哪里。爬虫跟踪这些已经找到的链接,并且尝试去发现对于搜索引擎来说不知道的一些文档。
索引。此功能组件负责解析每个页面,然后分析各种页面的元素,例如,文本内容,头部内容,结构化或者自定义过的特色部分,特殊的html标签,等等。
数据库。搜索引擎下载和分析的一些数据,都要进行存储。有些时候,它也叫做搜索引擎的索引。
结果引擎。结果引擎来进行页面的排名工作。它决定着哪些页面是最匹配用户的搜索请求的,并且按照何种有效而合理的次序来显示这些结果。这是根据搜索引擎的排名算法而决定的。它追寻的是这样一种理念,页面排名是有价值的,基于用户兴趣驱动的,所以对于SEO工作者来说这个是最感兴趣的,SEOer们的目标就是如何有效提高所关心的网站的页面排名。
Web服务器。搜索引擎web服务器包含了这样的一个基本的web页面,有一个用于用户输入感兴趣的关键词的文本框,并且当用户提交搜索动作时,将搜索出的结果合理的展示给用户。


文章评论 本文章有个评论