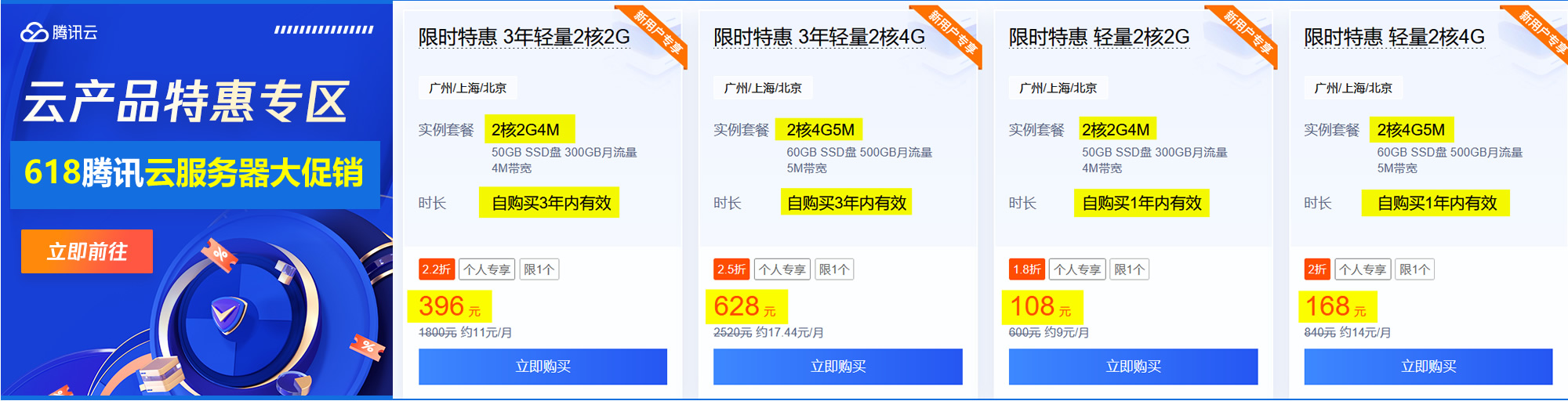


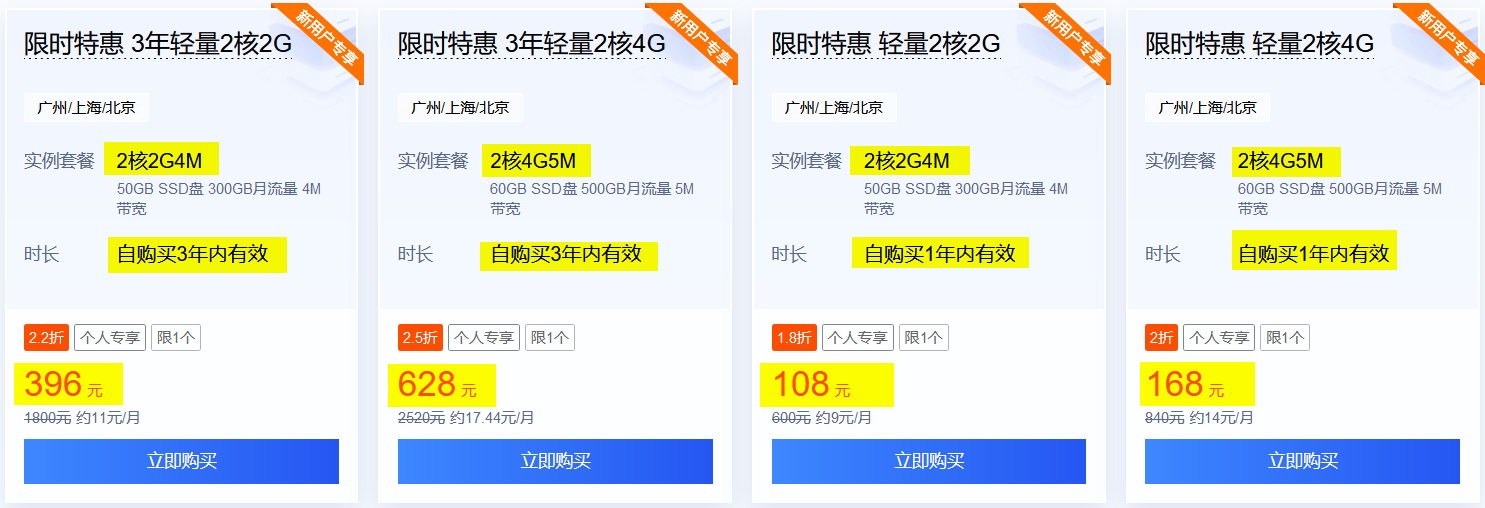

SEOER的研究对象就是搜索引擎,因此深入了解搜索引擎工作原理很有必要,网上也有很多介绍这方面的文章,但能称得上详细、形象、深入地进行剖析的少之又少。当然,笔者的博文可能也完全达不到所谓的详细、形象、深入三面俱到,但笔者会尽可能详尽、深入地阐述各个原理,以便对这些原理能有更深层次的认知。
一、抓取:其实在抓取前面还有一个过程没有描述在内,那就是爬行,也就是搜索引擎程序发现新网址的过程,只是这个过程大多伴随着抓取,除非你的这个URL上的内容没有什么价值(垃圾内容、重复内容、文字过少内容等)而被搜索引擎抓取程序直接跳过。搜索引擎爬行程序以数据表中已存在或新提交的链接顺藤摸瓜式地进行爬行以不断发现新的URL,抓取程序在分析并确定该URL的页面内容有价值后,便将其整个页面抓取下来放入到庞大的信息数据表中。新抓取的内容在进入信息数据表时,并不是一股脑地堆积在那,而是按照信息数据库中表的字段(如:网页URL、title、描述、正文内容、抓取时间、导出链接等)分门别类地将信息存储起来,以便满足后期的数据索引操作。
二、索引:在谈这个过程前,我们首先要理清搜索引擎索引数据表与信息数据表之间的关系,其实搜索引擎底层的数据存储本身就是一个关系数据库,索引数据表和信息数据表是两个独立的表,只是索引数据表和信息数据表是一对多的关系,这样或许更好理解。那么搜索引擎为什么需要索引数据表呢?我们不妨从信息量这个角度分析一下,就目前来看,搜索引擎的信息量在百亿级,而用户搜索某个关键字时响应速度在短短的2、3秒内,在这短短的2、3内不仅仅要完成数据的查询,而且还要完成数据的排序(关键词排名)。如果每次都要从这百亿级的数据中查询用户请求并处理排序,不仅减慢响应速度,而且还浪费了大量的计算资源,对服务器的压力也会更大。这个时候,搜索引擎就迫切希望将用户查询的信息锁定在一个范围,这个范围的信息量或许只有几千条、几百条,计算处理起来,效率要高很多,而索引数据表就是为解决这一问题出现的。
根据统计,汉语词语大约有9万多个,听起来很庞大,但对于计算机来讲处理起来恐怕会很轻松,而中文用户的搜索无外乎就是这几万个词语的组合(英文就更简单了,26个字母的组合)。如果用户搜索的是一连串儿的句子,那么要先经过搜索引擎的分词处理,比如 搜索:华普笔记本电脑,分词技术首先会按照汉语习惯进行划分,划分为:华普、笔记本、电脑,那么这三个常见词语在搜索引擎索引数据库表中都有对应的词条,此时搜索引擎将从信息数据表中筛选出关联索引数据表中3个词语的全部词条并取其交集词条展现给用户,如果用户单一搜索一个词语,那搜索引擎处理起来就更为简单,直接从信息数据表中筛选出索引数据表中该词所对应的词条即可。
三、排名:阐述这一原理,不得不说下搜索引擎爬行、抓取过程,影响关键词排名的因素很多,如:站内优化情况、外链质量及数量、pr等,那么这些排名因素搜索引擎也必须抓入数据库,纳入数据表作为特定URL的排名依据,其实影响网页排名指标的获取过程就是搜索引擎爬行、抓取的过程。最难理解的可能就是外链这一块儿,因为在抓取网页时,搜索引擎是捕捉不到他的导入链接的,其实搜索引擎在抓取一个页面时,已经将该页面的导出链接投票计算到了相应的页面,并将这一有效投票写入到了所指向的URL字段中(比如:votes字段),便于排名程序加以计算。当然,影响排名的因素很多,排名计算的具体方式我们也无从得知,因此这些不在我们的讨论之列。关于排名,大家可能还有一个问题,就是每个词语的排名是事先排序好了,还是当用户搜索时才进行排序,笔者给出的答案是后者,或许这一个现象可以揭秘笔者的答案:每一天甚至每一小时关键字排名都会出现波动。
笔者带病写博文,因此语言上可能有点儿费解,最后笔者PS张图给大家看下,作为宏观了解搜索引擎的三大原理示意图,如文中图所示。
本文来自 http://www.zhengzhouseo.org/post/sousuoyinqing-jingyan24.html 阿民的博客,转载请注明出处,谢谢!

文章评论 本文章有个评论